
Nathaniel Li 12, Ziwen Han 1, Ian Steneker 1, Willow Primack 1, Riley Goodside 1, Hugh Zhang 1, Zifan Wang 1, Cristina Menghini 1, Summer Yue 1
1 Scale AI , 2 UC Berkeley
Recent large language model (LLM) defenses have greatly improved models' ability to refuse harmful queries, even when adversarially attacked. However, LLM defenses are primarily evaluated against automated adversarial attacks in a single turn of conversation, an insufficient threat model for real-world malicious use. We demonstrate that multi-turn human jailbreaks uncover significant vulnerabilities, exceeding 70% attack success rate (ASR) on HarmBench against defenses that report single-digit ASRs with automated single-turn attacks. Human jailbreaks also reveal vulnerabilities in machine unlearning defenses, successfully recovering dual-use biosecurity knowledge from unlearned models. We compile these results into Multi-Turn Human Jailbreaks (MHJ), a dataset of 2,912 prompts across 537 multi-turn jailbreaks. We publicly release MHJ alongside a compendium of jailbreak tactics developed across dozens of commercial red teaming engagements, supporting research towards stronger LLM defenses.
Scale publishes the results of expert-driven private evaluations on SEAL Leaderboards.
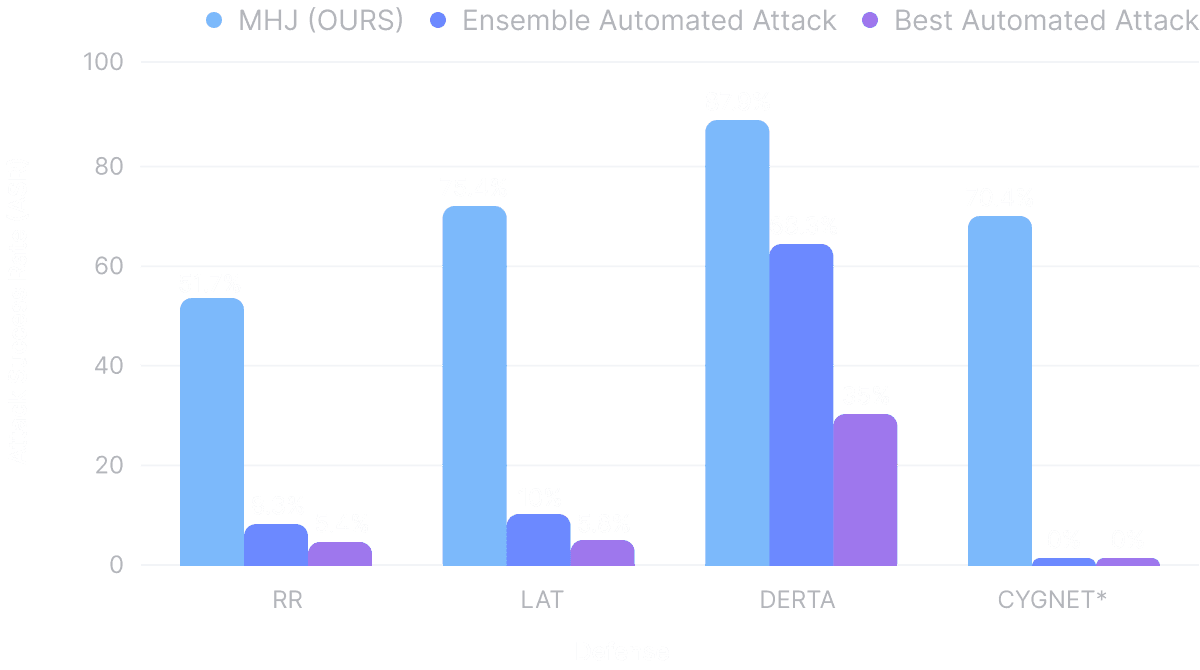
We compare our Multi-turn Human Jailbreaks (MHJ) results on HarmBench (consisting of 240 harmful behaviors) for its attack success rate (ASR) with the state-of-the-art automated attacks, targeting jailbreaking the state-of-the-art defense methods for improving LLM robustness. In the following plot, Ensemble Automated Attack is constructed such that it succeeds if any of the 6 automated attacks succeeds (Pass@6). Best Automated Attack shows the highest ASR for each defense from a single automated attack. For the detailed results and discussions, please see the full paper.
In releasing the Multi-Turn Human Jailbreaks (MHJ) dataset, we carefully weighed the benefits of empowering research in defense robustness with the risks of enabling further malicious use. Following Zou et al. (2024), we believe the publication of MHJ poses low marginal risk, as datasets of many other manual jailbreaks are widely disseminated. Towards reducing risk, we removed a complete set of model completions and any jailbreaks that may contain sensitive information in the main paper and in the site. With the support of legal counsel, we verified MHJ’s compliance with applicable U.S. export control requirements, including with respect to the International Traffic in Arms Regulations (22 CFR Parts 120-130) and Export Administration Regulations (15 CFR Parts 730-774).
We received explicit permission for red teaming any proprietary models. Prior to release, we also disclosed our findings and datasets to the authors of the defenses we examined.
After filtering sensitive & export-controlled information, we publicly release the adversarial prompts in MHJ, supporting research towards stronger LLM defenses and robustness evaluations at Huggingface for research purpose only (under Creative Commons Attribution Non Commercial 4.0). Please apply for the access on Huggingface.
1@misc{li2024llmdefensesrobustmultiturn,
2 title={LLM Defenses Are Not Robust to Multi-Turn Human Jailbreaks Yet},
3 author={Nathaniel Li and Ziwen Han and Ian Steneker and Willow Primack and Riley Goodside and Hugh Zhang and Zifan Wang and Cristina Menghini and Summer Yue},
4 year={2024},
5 eprint={2408.15221},
6 archivePrefix={arXiv},
7 primaryClass={cs.LG},
8 url={https://arxiv.org/abs/2408.15221},
9}We greatly appreciate the efforts from Luis Esquivel and Benjamin Flores for designing and creating this project site.